Post your burning questions about ontologies and knowlege graphs here
-
FirstLight
- Site Admin
- Posts: 35
- Joined: Sun Feb 27, 2022 1:58 pm
Post your burning questions about ontologies and knowlege graphs here
We all have questions about Knowledge Graphs, especially as they relate to our content applications. Use this thread to ask them. Do not fear embarrassment no matter how fundamental or off the bleeding edge. It's OK to have such questions, or even be mistaken or have existing misconceptions. We’re going where few have gone before in our discipline. Do not fear asking anything for fear of sounding dumb – let’s be dumb; that’s how we get properly informed and smarter. If you can answer or provide a good reference or resource, great. If not we'll invite some experts in the field to help us answer them. I recall a wise technical writing instructor who once said, “Recognize and document your perplexities. Chances are high that others experience the very same.”
-
FirstLight
- Site Admin
- Posts: 35
- Joined: Sun Feb 27, 2022 1:58 pm
Knowledge Graph Generation
Q. Can we generate a knowledge graph based on a DITA schema?
Background: Typically, one creates an ontology, which serves as a generalized model (not comprised of specific data instances), as a base on which to create a knowledge graph As I understand it, a knowledge graph is essentially an ontology + references (URIs) to specific data. Let’s use DITA as the example (could be any XML or JSON I assume), but DITA is a common and rick schema to use as an example.
Let’s assume we have a content store full of DITAMaps and DITA topics. Could we point a tool (provide a few example tools), that can read the DITAmaps and construct a knowledge graph without the pre-existence of an ontology?
Q. If a pre-existing ontology is required, can we generate an ontology solely from the public DITA DTDs (schema), or do we still need to create an explicit ontology for it?
Q. Let’s take it a bit further. If a pre-existing ontology is required, or, or having an explicitly-defined ontology? A gentleman by the name of Colin Maudry created an ontology for DITA back in 2015 and provided it as a contribution to the DITA Open Toolkit. Although that ontology might need to be updated, would basing a knowledge graph on such an ontology for a DITA corpus be the best approach? If so, what are the inputs and outputs? Can we use the ontology in a tool plus and scan the DITA content store to automatically generate a knowledge graph without needing to manually populate the graph? If so, do the DITA DTDs play any role as input?
Michael
Background: Typically, one creates an ontology, which serves as a generalized model (not comprised of specific data instances), as a base on which to create a knowledge graph As I understand it, a knowledge graph is essentially an ontology + references (URIs) to specific data. Let’s use DITA as the example (could be any XML or JSON I assume), but DITA is a common and rick schema to use as an example.
Let’s assume we have a content store full of DITAMaps and DITA topics. Could we point a tool (provide a few example tools), that can read the DITAmaps and construct a knowledge graph without the pre-existence of an ontology?
Q. If a pre-existing ontology is required, can we generate an ontology solely from the public DITA DTDs (schema), or do we still need to create an explicit ontology for it?
Q. Let’s take it a bit further. If a pre-existing ontology is required, or, or having an explicitly-defined ontology? A gentleman by the name of Colin Maudry created an ontology for DITA back in 2015 and provided it as a contribution to the DITA Open Toolkit. Although that ontology might need to be updated, would basing a knowledge graph on such an ontology for a DITA corpus be the best approach? If so, what are the inputs and outputs? Can we use the ontology in a tool plus and scan the DITA content store to automatically generate a knowledge graph without needing to manually populate the graph? If so, do the DITA DTDs play any role as input?
Michael
-
ClaudetteH
- Posts: 6
- Joined: Fri Mar 25, 2022 6:26 pm
Re: Post your burning questions about ontologies and knowlege graphs here
OK, here's my stupid question about knowledge graphs. We've all been throwing around this term a lot. I have a background in SEO, so when I think knowledge graphs, I think of Google Knowledge Graphs, like this: https://www.bleepstatic.com/content/pos ... _Graph.png. Is this team basically talking about the same thing, but maybe a customized implementation for our individual teams' purposes?
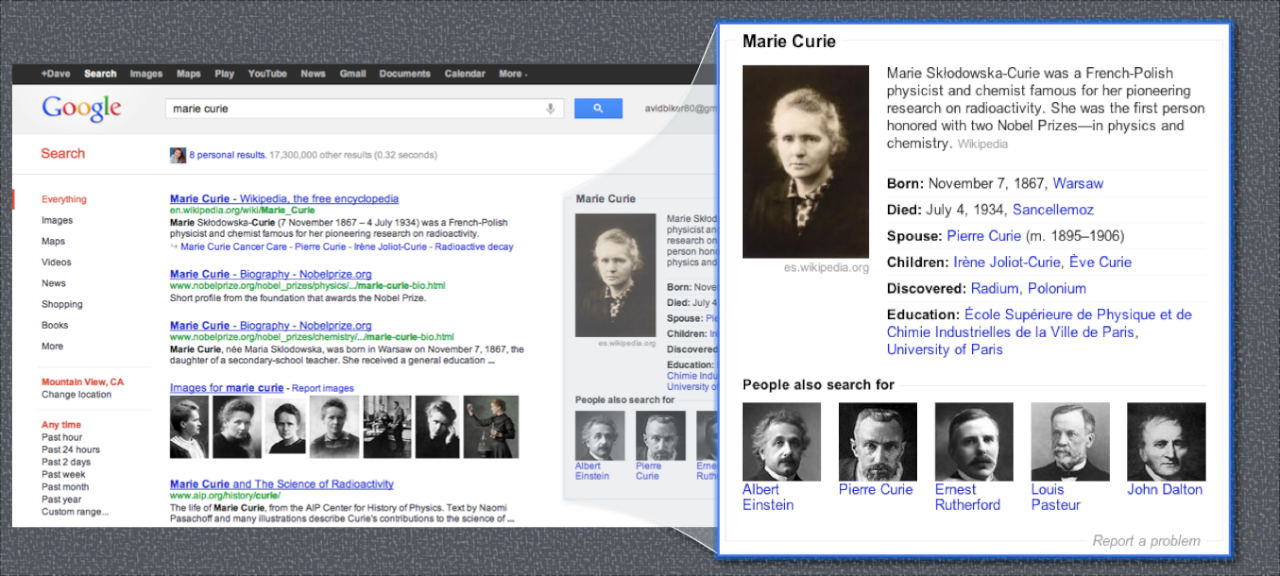{kind=link}
-
FirstLight
- Site Admin
- Posts: 35
- Joined: Sun Feb 27, 2022 1:58 pm
Re: Post your burning questions about ontologies and knowlege graphs here
Your example would be a specific application of a knowledge graph. The association to the content is automated b/c the graph created that inference based on existing known relationships we seed in the original graph.
Imagine graphic your entire content corpus - the application can be related to content recommendations that are highly relevant that are not prescriptively defined beforehand. Again, just one of many potential applications.
Regards,
Michael
Imagine graphic your entire content corpus - the application can be related to content recommendations that are highly relevant that are not prescriptively defined beforehand. Again, just one of many potential applications.
Regards,
Michael
-
ClaudetteH
- Posts: 6
- Joined: Fri Mar 25, 2022 6:26 pm
Re: Post your burning questions about ontologies and knowlege graphs here
Ah! Got it! Thanks. 

-
FirstLight
- Site Admin
- Posts: 35
- Joined: Sun Feb 27, 2022 1:58 pm
Re: Post your burning questions about ontologies and knowlege graphs here
Heather Hedden, author of The Accidental Taxonomist, did a webinar recently. There were many questions after her talk on taxonomy - too many in fact. Heather was kind enough to answer them in writing and the questions and answers were quite informative. I am re-posting them here for your use. As I mentioned, we have Heather tentatively lined up to talk to us at the June meeting - it's always an education listening to her.
BrightTALK webinar “Understanding Facets and Taxonomies” April 12, 2022, with Heather Hedden
Q: Some companies have established a rich dedicated terminology management system that’s the
source of truth for very term management. Then they introduce a taxonomy/ontology/graph platform
such as PoolParty. Does a taxonomy platform replace a term management platform or do we
integrate them so that all can be harmonized?
Either approach could be taken, and it depends on the specific software products as to which works
best: keeping data in two systems and integrating then with an API, or migrating data from one
system to be with data in another, namely from a terminology management system to a SKOS-based
taxonomy/thesaurus management system (such as PoolParty). SKOS supports all kinds of
knowledge organization systems, including terminologies (multiple languages, alternative labels,
multiple definitions, examples, notations, etc.). Unless there is some important, additional feature in
the terminology management system, which the SKOS taxonomy/thesaurus management system
lacks, or you have a very large terminology already managed in a terminology system (that is much
larger than your taxonomy will be), I think it probably makes more sense to migrate the terms and their
definitions and other data from the terminology management system to the SKOS system, thus
replacing the terminology management system.
In any case, SKOS taxonomies are not just another way of managing terminologies, but extend the
possibilities of dealing with terms and the concepts they denote, and of linking them.
SKOS is the entry door into the world of knowledge graphs. With it, organizations potentially create
holistic views of all their knowledge around their business objects, the relationships between them,
where they are further described or mentioned (variously contextualized) in all the existing data and
content sources, and indeed the names and identifiers used for them.
Q: What should come first, the ontology (defining concepts and their relationship) or defining the
taxonomy(s) (defining the facets) and the pros and cons of which way? There seems to be great
debate about that.
Yes, that’s the classic top-down vs. bottom-up approach question about taxonomy design, which also
applies to an ontology. After defining your use case and taxonomy scope, be practical and start with
what you have: existing taxonomies, glossaries, term lists, metadata schema, spreadsheet tables of
term types or other metadata. An analysis of this data, especially column headers and worksheet tabs
will suggest candidates for taxonomy facets or ontology classes (which can be the same, but they
function differently in a front-end application for a different query experience). It’s much more
common that an organization already has components of a taxonomy or taxonomy but no ontology,
and thus, an ontology is added to an existing taxonomy and other named entity controlled
vocabularies. A further analysis of business objects or entities that have a business use case and
perhaps some brainstorming with stakeholders can suggest additional taxonomy facets or ontology
classes. Once you have the ontology classes defined with example entities or concepts belonging to a
class, you can then define the attributes and the relationships. Further detailed building out of the
taxonomy with more specific concepts may then follow.
Additionally, whether the semantic knowledge model is to be developed from the point of view of
concrete expressions (instances), or from the point of view of abstract classes, depends above all
also on what one (the knowledge modeler) already knows about the domain.
Whether the semantic knowledge model is to be developed from the point of view of concrete
expressions (instances), or from the point of view of abstract classes, depends above all also on what
one (the knowledge modeler) already knows about the domain.. Sometimes one does not have the
choice at all whether one advances by means of induction, deduction or abduction, if one wants to
develop and model the domain. In many cases it is a mixed approach.
Q: Is the use of a visual mind-mapping tool useful for starting the design of a taxonomy? If so, how is
it best used?
For a taxonomy, which is one or more hierarchies of concepts, a mind-mapping tool is not needed.
Most people start out creating hierarchical taxonomies in a spreadsheet program, with deeper levels
of hierarchy in succeeding columns to the right. Additionally, for initial brainstorming, instead of
mind-mapping, it is recommended to start with card-sorting to lay out an initial structure of the
knowledge domain. See www.poolparty.biz/poolparty-cardsorting
When designing an ontology, however, some people find that a mind mapping tool is useful, especially
for naming the semantic relationships between classes.
Q: For support content, we need to enable search based on the user-search terms (aka folksonomy)
that might differ from a well-architected taxonomy. Do we use the folksonomy as synonyms as
alternate or hidden attributes to the formal taxonomy to make both worth together.
To clarify, user search terms/strings is not the same as a folksonomy, unless you capture, store, and
make the terms available for reuse. A displayable, reusable search term set is what would be called a
folksonomy, although such implementations are rare.
Enabling search based on user search strings, in general, is standard and expected. User search
strings must match concept labels, whether preferred, alternative, or hidden. Preferred labels are what
display in a hierarchical display. Preferred and alternative labels are what display in an alphabetical,
type-ahead, or search-suggest term display. Hidden labels are designated to never display to users,
but they may still match user search strings. The user is then redirected to the search result set
without seeing that their search string matched a hidden label of a concept tagged to the content.
In taxonomy creation and editing, it is useful to analyze a search log report to consider adding some
of those search strings as alternative or hidden labels for concepts.
In addition to search logs, there are several other sources to continuously expand an existing
taxonomy, including text corpus analysis.
Q: What is the difference between alternative and hidden labels?
Hidden labels are essentially a sub-type of alternative labels. If your taxonomy is configured to display
alternative labels to end-users, you may designate certain labels as hidden labels so that they will not
display, because they are not appropriate for display. However, this all depends on your
implementation.
Q: It's more that there's SO MANY items on Etsy, that there needs to be many filters to narrow down
Searches
Yes, good observation. If there are many, numerous items of the same specific subcategory, then the
method of further refinement, refinement by attributes, needs to be quite specific and extensive.
Q: In SKOS, how do you differentiate between an attribute and a hierarchical concept?
SKOS does not have a special feature for attributes and thus does not have an explicit way to
differentiate attributes and hierarchical concepts. But SKOS is flexible in its use. Since a controlled
vocabulary of attributes lives outside of the hierarchy (although connected through relationships), in
SKOS, a separate concept scheme should be used for maintaining attributes, separate from the
concept scheme(s) for the hierarchical concepts.
Q: If you have to share top 5 do's and don'ts in building a taxonomy what would they be?
That sounds like it should be the topic of an entire, new blog post.
Do:
1. Have a specific use case, set of users in mind (if not actually doing user interviews), and
identified content upon which to base the taxonomy initially
2. Create alternative labels that are appropriate, sufficient but not excessive
3. Follow standards for design of ANSI/NISO Z39.19 as appropriate
4. Document the taxonomy and tagging, policies, and establish a governance plan for continued
maintenance
5. Develop taxonomy as part of a larger metadata, content management, or data management
strategy
Don’t:
1. Create a deep classification system
2. Fully mirror a navigation system, sitemap, or table of contents for a taxonomy hierarchy
3. Reuse a different vocabulary designed for a different purpose (such as a glossary or
terminology) for an information retrieval taxonomy
4. Create a taxonomy alone (without involving stakeholders and/or colleagues)
5. Maintain a large taxonomy in spreadsheets
Q: I'm interested in determining the best language to use to add schema microdata to my personal
website so that my music related content is easier to find via google search and ALEXA semantic
search. Should I tag using JSON-LD or RDFa?
I don;’t know but I search for an answer and found:
https://www.quora.com/What-is-the-diffe ... Fa-JSON-LD
which says at the end: Google recommends using JSON-LD for structured data whenever possible.
Q: How often are we reinventing the wheel with these taxonomies? Do we really need to keep building
these lists for every company and every department?
It is indeed becoming less common to build new taxonomies from scratch. But taxonomies get out of
date, or were built for only a limited use (one department), and need to be revised, merged, expanded,
etc. New companies, startups, and new lines of business need to build new taxonomies. Many
companies are unique and need to build their own taxonomies, but it is true that for describing
products and services of certain businesses, the same set of metadata can be shared. There are
taxonomies available for sale/for licence.
Q: How does the poolparty tool when integrating the taxonomy in another tool? Is this synchronized
automatically?
PoolParty has integrations with RWS Tridion, SharePoint, AEM, and Drupal. For other integrations,
custom development can be done with the Poolparty Thesaurus API. But in either case (out-o-the-box
or custom integration) the result is an automatic synchronization of the taxonomy in PoolParty with
the taxonomy in the frontend application.
Q: How do you determine what kind of taxonomy you need?
It depends on the nature of the content. For example, research articles are suited for a thesaurus, a
public website is suited for a hierarchical taxonomy, an intranet is suited for faceted taxonomy,
e-commerce for products is suited for a hierarchical taxonomy plus attributes.
Q: How do you add the taxonomy to documents? Is it a manual process or is there any automation
behind?
This is called tagging, indexing, categorizing, and sometimes annotation. It can be manual or
automated, or a combination of automated suggestions with human review/approval with
supplemental tagging. Fully automated can be done in a taxonomy management system that
combines auto-tagging, such as PoolParty, whereas manual or automated with manual review is done
in an application, such as content management system or SharePoint. (Where PoolParty has an
integration, such as in SharePoint or AEM, then automated indexing from PoolParty is displayed for
human review in the other system.)
Q: How are decisions made on what/if attributes are available as filters?
The taxonomist considers how many item results there are with each category and combined filters: a
few to select from (3 or more), but not too many to not fit in one page display. Others might contribute
to the decision, such as a product manager or user experience designer.
Q: How do you differentiate a controlled vocabulary from a thesauri?
A thesaurus is a type of controlled vocabulary with specific structure and features (broader, narrower,
and related term relationships, alternative labels or used-from terms, scope notes). But sometimes
people use “controlled vocabulary” to refer to a term list that does not have a hierarchy.
Q: What happens when, for example, new products are introduced that may not fit into existing
categories?
If there are multiple products of a certain type, then a new subcategory can be created. Otherwise an
existing category can be renamed slightly to slightly broaden its meaning in order to include the new
product type.
Q: How was the name of the W3 standard called for Taxonomy to make it machine readable?
The World Wide Web Consortium is the organization that has developed standards and guidelines for
the World Wide Web and the Semantic Web. The abbreviation for World Wide Web Consortium is
W3C. The standard for taxonomies from the W3C is SKOS (Simple Knowledge Organization System).
Q: Can it be said that Attributes are similar 'tags' over many different categories? This is why they do
not necessarily belong to the Taxonomy?
The word “tags” is not strictly defined. So, yes, you can call attributes tags, since they are tagged, as
metadata, to content. And, yes, attributes can be tagged over different categories. Actually,
“categories” is not strictly defined, but they are understood to be something in a hierarchy: either any
taxonomy concept in a hierarchy, or just the top levels of a hierarchy, but just not named entity
instances.
Q: Does software like Pool Party primarily manage the backend taxonomy? Or can you also use it to
provide a front end search UI for customers that is based on the taxonomy?
Yes, PoolParty and similar taxonomy management software managed the backend of the taxonomy. It
can integrate with a frontend UI for customers that is based on the taxonomy. However, the vendor
PoolParty does offer its own frontend UI, based on its API, which is called GraphSearch, a faceted
search user interface. Demos are at https://elasticsearch.poolparty.biz/GraphSearch/ and
https://vocabulary.semantic-web.at/GraphSearch/
Q: Do you have any tips for finding competitive intelligence resources to inform product taxonomy
development? Especially when working in a niche product vertical. Thanks!
If it’s for a public ecommerce implementation, then, of course, you can look at competitor ecommerce
websites. I have done that before when I consulted on an ecommerce taxonomy.
Q: Do you feel that a certain named subcategory should always appear under ONE higher category, or
is it okay for the same named subcategory to appear under multiple higher categories? What's the
best practice?
Yes, sometimes a subcategory can appear under more than one broader category, if it is a valid
hierarchical relationship (according to the standards) in both cases. This way, users browsing down
different hierarchical paths still come to the desired subcategory. This is called polyhierarchy, because
the subcategory (concept) belongs to more than one hierarchy. It appears to the end user in more
than one place, but it is the same subcategory tagged to the same content in either location.
Q: Can you show examples online of facets, please?
The examples I showed were:
www.linkedin.com/jobs/search Click on “All filters” and the pane that pops out to the right contains
taxonomy facets: Experience Level, Company, Job Type, one-site/Remote, Location, Industry, Job
Function.
https://journals.plos.org/climate/searc ... q=&sortOrd
er=DATE_NEWEST_FIRST&page=1
In the left margin are facets: Journal, Subject Area, Article Type, Author, etc.
BrightTALK webinar “Understanding Facets and Taxonomies” April 12, 2022, with Heather Hedden
Q: Some companies have established a rich dedicated terminology management system that’s the
source of truth for very term management. Then they introduce a taxonomy/ontology/graph platform
such as PoolParty. Does a taxonomy platform replace a term management platform or do we
integrate them so that all can be harmonized?
Either approach could be taken, and it depends on the specific software products as to which works
best: keeping data in two systems and integrating then with an API, or migrating data from one
system to be with data in another, namely from a terminology management system to a SKOS-based
taxonomy/thesaurus management system (such as PoolParty). SKOS supports all kinds of
knowledge organization systems, including terminologies (multiple languages, alternative labels,
multiple definitions, examples, notations, etc.). Unless there is some important, additional feature in
the terminology management system, which the SKOS taxonomy/thesaurus management system
lacks, or you have a very large terminology already managed in a terminology system (that is much
larger than your taxonomy will be), I think it probably makes more sense to migrate the terms and their
definitions and other data from the terminology management system to the SKOS system, thus
replacing the terminology management system.
In any case, SKOS taxonomies are not just another way of managing terminologies, but extend the
possibilities of dealing with terms and the concepts they denote, and of linking them.
SKOS is the entry door into the world of knowledge graphs. With it, organizations potentially create
holistic views of all their knowledge around their business objects, the relationships between them,
where they are further described or mentioned (variously contextualized) in all the existing data and
content sources, and indeed the names and identifiers used for them.
Q: What should come first, the ontology (defining concepts and their relationship) or defining the
taxonomy(s) (defining the facets) and the pros and cons of which way? There seems to be great
debate about that.
Yes, that’s the classic top-down vs. bottom-up approach question about taxonomy design, which also
applies to an ontology. After defining your use case and taxonomy scope, be practical and start with
what you have: existing taxonomies, glossaries, term lists, metadata schema, spreadsheet tables of
term types or other metadata. An analysis of this data, especially column headers and worksheet tabs
will suggest candidates for taxonomy facets or ontology classes (which can be the same, but they
function differently in a front-end application for a different query experience). It’s much more
common that an organization already has components of a taxonomy or taxonomy but no ontology,
and thus, an ontology is added to an existing taxonomy and other named entity controlled
vocabularies. A further analysis of business objects or entities that have a business use case and
perhaps some brainstorming with stakeholders can suggest additional taxonomy facets or ontology
classes. Once you have the ontology classes defined with example entities or concepts belonging to a
class, you can then define the attributes and the relationships. Further detailed building out of the
taxonomy with more specific concepts may then follow.
Additionally, whether the semantic knowledge model is to be developed from the point of view of
concrete expressions (instances), or from the point of view of abstract classes, depends above all
also on what one (the knowledge modeler) already knows about the domain.
Whether the semantic knowledge model is to be developed from the point of view of concrete
expressions (instances), or from the point of view of abstract classes, depends above all also on what
one (the knowledge modeler) already knows about the domain.. Sometimes one does not have the
choice at all whether one advances by means of induction, deduction or abduction, if one wants to
develop and model the domain. In many cases it is a mixed approach.
Q: Is the use of a visual mind-mapping tool useful for starting the design of a taxonomy? If so, how is
it best used?
For a taxonomy, which is one or more hierarchies of concepts, a mind-mapping tool is not needed.
Most people start out creating hierarchical taxonomies in a spreadsheet program, with deeper levels
of hierarchy in succeeding columns to the right. Additionally, for initial brainstorming, instead of
mind-mapping, it is recommended to start with card-sorting to lay out an initial structure of the
knowledge domain. See www.poolparty.biz/poolparty-cardsorting
When designing an ontology, however, some people find that a mind mapping tool is useful, especially
for naming the semantic relationships between classes.
Q: For support content, we need to enable search based on the user-search terms (aka folksonomy)
that might differ from a well-architected taxonomy. Do we use the folksonomy as synonyms as
alternate or hidden attributes to the formal taxonomy to make both worth together.
To clarify, user search terms/strings is not the same as a folksonomy, unless you capture, store, and
make the terms available for reuse. A displayable, reusable search term set is what would be called a
folksonomy, although such implementations are rare.
Enabling search based on user search strings, in general, is standard and expected. User search
strings must match concept labels, whether preferred, alternative, or hidden. Preferred labels are what
display in a hierarchical display. Preferred and alternative labels are what display in an alphabetical,
type-ahead, or search-suggest term display. Hidden labels are designated to never display to users,
but they may still match user search strings. The user is then redirected to the search result set
without seeing that their search string matched a hidden label of a concept tagged to the content.
In taxonomy creation and editing, it is useful to analyze a search log report to consider adding some
of those search strings as alternative or hidden labels for concepts.
In addition to search logs, there are several other sources to continuously expand an existing
taxonomy, including text corpus analysis.
Q: What is the difference between alternative and hidden labels?
Hidden labels are essentially a sub-type of alternative labels. If your taxonomy is configured to display
alternative labels to end-users, you may designate certain labels as hidden labels so that they will not
display, because they are not appropriate for display. However, this all depends on your
implementation.
Q: It's more that there's SO MANY items on Etsy, that there needs to be many filters to narrow down
Searches
Yes, good observation. If there are many, numerous items of the same specific subcategory, then the
method of further refinement, refinement by attributes, needs to be quite specific and extensive.
Q: In SKOS, how do you differentiate between an attribute and a hierarchical concept?
SKOS does not have a special feature for attributes and thus does not have an explicit way to
differentiate attributes and hierarchical concepts. But SKOS is flexible in its use. Since a controlled
vocabulary of attributes lives outside of the hierarchy (although connected through relationships), in
SKOS, a separate concept scheme should be used for maintaining attributes, separate from the
concept scheme(s) for the hierarchical concepts.
Q: If you have to share top 5 do's and don'ts in building a taxonomy what would they be?
That sounds like it should be the topic of an entire, new blog post.
Do:
1. Have a specific use case, set of users in mind (if not actually doing user interviews), and
identified content upon which to base the taxonomy initially
2. Create alternative labels that are appropriate, sufficient but not excessive
3. Follow standards for design of ANSI/NISO Z39.19 as appropriate
4. Document the taxonomy and tagging, policies, and establish a governance plan for continued
maintenance
5. Develop taxonomy as part of a larger metadata, content management, or data management
strategy
Don’t:
1. Create a deep classification system
2. Fully mirror a navigation system, sitemap, or table of contents for a taxonomy hierarchy
3. Reuse a different vocabulary designed for a different purpose (such as a glossary or
terminology) for an information retrieval taxonomy
4. Create a taxonomy alone (without involving stakeholders and/or colleagues)
5. Maintain a large taxonomy in spreadsheets
Q: I'm interested in determining the best language to use to add schema microdata to my personal
website so that my music related content is easier to find via google search and ALEXA semantic
search. Should I tag using JSON-LD or RDFa?
I don;’t know but I search for an answer and found:
https://www.quora.com/What-is-the-diffe ... Fa-JSON-LD
which says at the end: Google recommends using JSON-LD for structured data whenever possible.
Q: How often are we reinventing the wheel with these taxonomies? Do we really need to keep building
these lists for every company and every department?
It is indeed becoming less common to build new taxonomies from scratch. But taxonomies get out of
date, or were built for only a limited use (one department), and need to be revised, merged, expanded,
etc. New companies, startups, and new lines of business need to build new taxonomies. Many
companies are unique and need to build their own taxonomies, but it is true that for describing
products and services of certain businesses, the same set of metadata can be shared. There are
taxonomies available for sale/for licence.
Q: How does the poolparty tool when integrating the taxonomy in another tool? Is this synchronized
automatically?
PoolParty has integrations with RWS Tridion, SharePoint, AEM, and Drupal. For other integrations,
custom development can be done with the Poolparty Thesaurus API. But in either case (out-o-the-box
or custom integration) the result is an automatic synchronization of the taxonomy in PoolParty with
the taxonomy in the frontend application.
Q: How do you determine what kind of taxonomy you need?
It depends on the nature of the content. For example, research articles are suited for a thesaurus, a
public website is suited for a hierarchical taxonomy, an intranet is suited for faceted taxonomy,
e-commerce for products is suited for a hierarchical taxonomy plus attributes.
Q: How do you add the taxonomy to documents? Is it a manual process or is there any automation
behind?
This is called tagging, indexing, categorizing, and sometimes annotation. It can be manual or
automated, or a combination of automated suggestions with human review/approval with
supplemental tagging. Fully automated can be done in a taxonomy management system that
combines auto-tagging, such as PoolParty, whereas manual or automated with manual review is done
in an application, such as content management system or SharePoint. (Where PoolParty has an
integration, such as in SharePoint or AEM, then automated indexing from PoolParty is displayed for
human review in the other system.)
Q: How are decisions made on what/if attributes are available as filters?
The taxonomist considers how many item results there are with each category and combined filters: a
few to select from (3 or more), but not too many to not fit in one page display. Others might contribute
to the decision, such as a product manager or user experience designer.
Q: How do you differentiate a controlled vocabulary from a thesauri?
A thesaurus is a type of controlled vocabulary with specific structure and features (broader, narrower,
and related term relationships, alternative labels or used-from terms, scope notes). But sometimes
people use “controlled vocabulary” to refer to a term list that does not have a hierarchy.
Q: What happens when, for example, new products are introduced that may not fit into existing
categories?
If there are multiple products of a certain type, then a new subcategory can be created. Otherwise an
existing category can be renamed slightly to slightly broaden its meaning in order to include the new
product type.
Q: How was the name of the W3 standard called for Taxonomy to make it machine readable?
The World Wide Web Consortium is the organization that has developed standards and guidelines for
the World Wide Web and the Semantic Web. The abbreviation for World Wide Web Consortium is
W3C. The standard for taxonomies from the W3C is SKOS (Simple Knowledge Organization System).
Q: Can it be said that Attributes are similar 'tags' over many different categories? This is why they do
not necessarily belong to the Taxonomy?
The word “tags” is not strictly defined. So, yes, you can call attributes tags, since they are tagged, as
metadata, to content. And, yes, attributes can be tagged over different categories. Actually,
“categories” is not strictly defined, but they are understood to be something in a hierarchy: either any
taxonomy concept in a hierarchy, or just the top levels of a hierarchy, but just not named entity
instances.
Q: Does software like Pool Party primarily manage the backend taxonomy? Or can you also use it to
provide a front end search UI for customers that is based on the taxonomy?
Yes, PoolParty and similar taxonomy management software managed the backend of the taxonomy. It
can integrate with a frontend UI for customers that is based on the taxonomy. However, the vendor
PoolParty does offer its own frontend UI, based on its API, which is called GraphSearch, a faceted
search user interface. Demos are at https://elasticsearch.poolparty.biz/GraphSearch/ and
https://vocabulary.semantic-web.at/GraphSearch/
Q: Do you have any tips for finding competitive intelligence resources to inform product taxonomy
development? Especially when working in a niche product vertical. Thanks!
If it’s for a public ecommerce implementation, then, of course, you can look at competitor ecommerce
websites. I have done that before when I consulted on an ecommerce taxonomy.
Q: Do you feel that a certain named subcategory should always appear under ONE higher category, or
is it okay for the same named subcategory to appear under multiple higher categories? What's the
best practice?
Yes, sometimes a subcategory can appear under more than one broader category, if it is a valid
hierarchical relationship (according to the standards) in both cases. This way, users browsing down
different hierarchical paths still come to the desired subcategory. This is called polyhierarchy, because
the subcategory (concept) belongs to more than one hierarchy. It appears to the end user in more
than one place, but it is the same subcategory tagged to the same content in either location.
Q: Can you show examples online of facets, please?
The examples I showed were:
www.linkedin.com/jobs/search Click on “All filters” and the pane that pops out to the right contains
taxonomy facets: Experience Level, Company, Job Type, one-site/Remote, Location, Industry, Job
Function.
https://journals.plos.org/climate/searc ... q=&sortOrd
er=DATE_NEWEST_FIRST&page=1
In the left margin are facets: Journal, Subject Area, Article Type, Author, etc.